GPT-SoVITS最近一直很火,可以用一分钟的数据集克隆出对应的声音,而且具有较高的音色还原度和准确度,那么今天就来玩一玩尝试一下
由于之前玩炼丹的时候还留下了很多余额,因此我们今天也会用到autodl来进行对应的算力支持,其较低的价格和现成打包好的项目都是一个很大的优势
准备
Autodl账号和对应的余额(不需要很多,熟练了一两块就够训练一次)
可以正常访问网络的环境
想要克隆的示例音频(在这里我使用了小鸟游星野的语音,因为大叔实在太!可!爱!了!不过实际操作中请注意版权问题)
训练
开机
首先我们进入autodl充值余额开机,你可以直接进入这里然后点击创建实例开机:CodeWithGPU | 能复现才是好算法
我这里选择了内蒙区的A5000,比较适中的价格和还可以的算力,非常完美,唯一美中不足的就是有的时候可能会没有卡
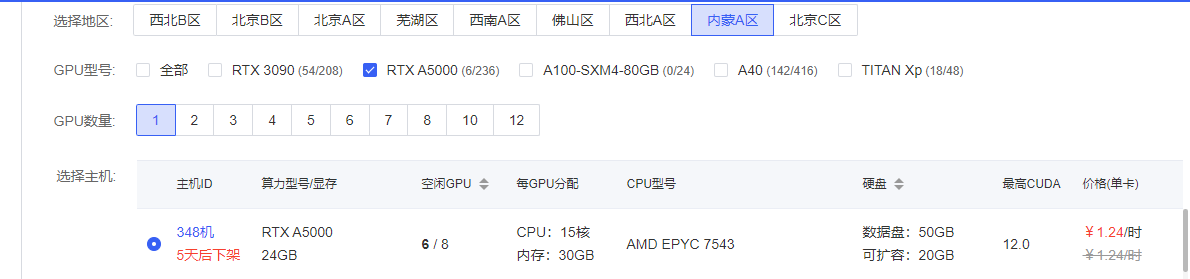

然后我们创建实例
由于是按量计费,请在这步后尽量抓紧时间你也可以选择在配环境阶段无卡开机,这样比较便宜
基础操作
我们在开机后首先需要打开Autopanel和JupyterLab,前者用来关联网盘(建议阿里网盘),后者用来操作模型的训练

然后我们打开JupyterLab,正式开始训练
在终端中输入
echo {}> ~/GPT-SoVITS/i18n/locale/en_US.json && source activate GPTSoVits && cd ~/GPT-SoVITS/ && python webui.pyWebUI所有新窗口均使用public URL的gradio地址打开,点击下面那个链接就会弹出网页,不是上面那个9874的链接。
数据集准备
我准备的是直接提取自游戏的干净原声,因此我不需要进行提取人声的操作,详细请看官方wiki:AutoDL教程(只要几块钱,方便) · 语雀
然后我们进行切分,从这步开始我们会用到显卡,因此之前用无卡模式运行的可以正常有卡开机了
在切割音频前建议把所有音频拖进音频软件(如au、剪映)调整音量,最大音量调整至-9dB到-6dB,过高的删除
输入路径是上面的原音频的文件夹路径,如果刚刚经过了UVR5处理那么就是uvr5_opt这个文件夹。输出路径默认是output/slicer_opt。建议可以调整的参数有min_length、min_interval和max_sil_kept单位都是ms。min_length根据显存大小调整,显存越小调越小。min_interval根据音频的平均间隔调整,如果音频太密集可以适当调低。max_sil_kept会影响句子的连贯性,不同音频不同调整,不会调的话保持默认。其他参数不建议调整。当然也可以使用其他切分工具切分。
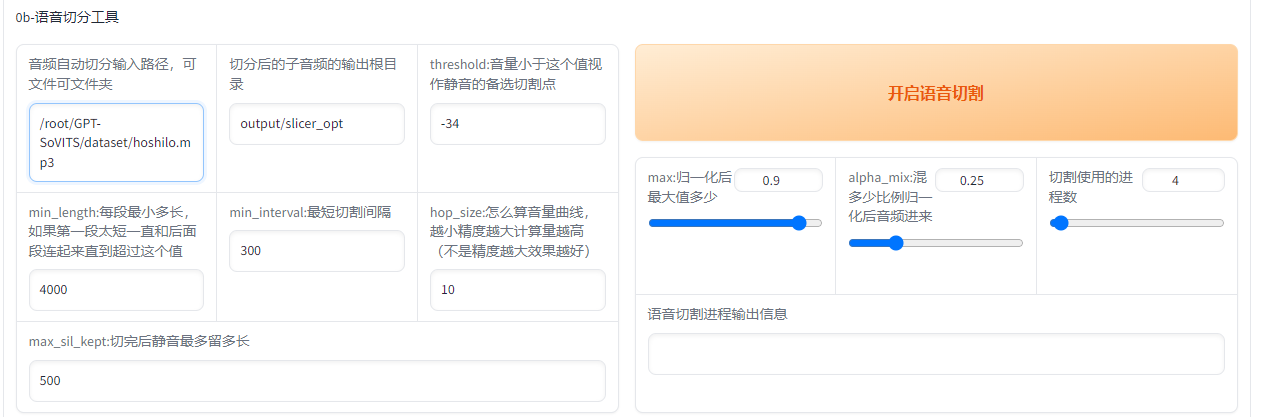
如果不了解的话默认数据不需要变动即可,记得在路径前加/root/,然后开启语音切割
切分完后文件在GPT-SoVITS\output\slicer_opt。打开切分文件夹,排序方式选大小,将时长超过 显存数 秒的音频手动切分至 显存数 秒以下。比如显卡是A5000 显存是24g,那么就要将超过24秒的音频手动切分至24s以下
这步完成后我们进行打标操作,默认路径是/root/GPT-SoVITS/output/slicer_opt(如果是外语如日语等建议手动上传打标或者可以使用这个工具)

终端中出现进度条表明操作正确,稍后结果会输出在.../output/asr_opt中
我因为是日语dataset,需要使用日语模型,因此参考这个在本地进行了打标操作
然后为了提高我们的训练效率和提升训练成果,我们进行对应的校对操作(非必须,但建议)
我们输入上一步拿到的打标list点击下面的打开webui,点击终端里的链接开始进行校对工作


完成保存即可,最后会得到这个list文件

训练
首先进行输出list,看这张图就好
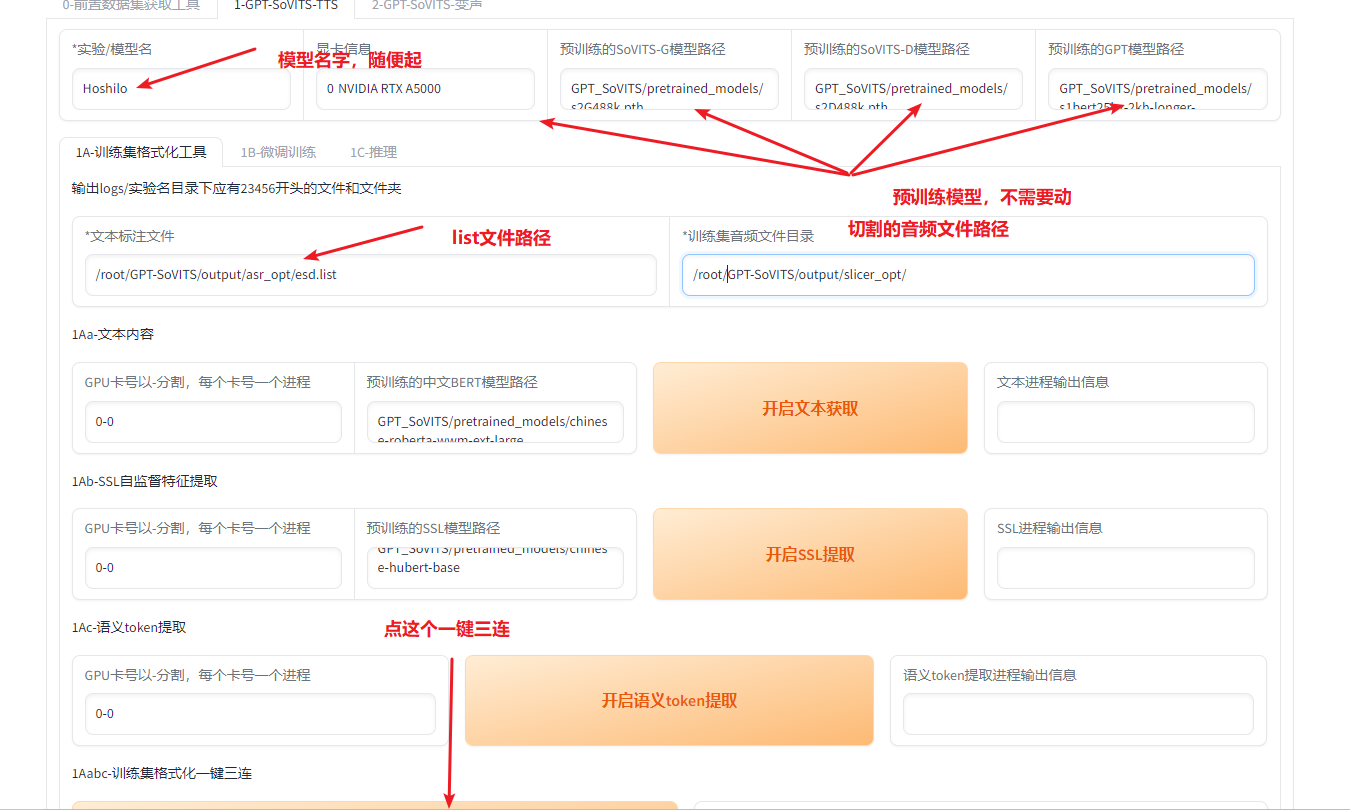
然后点击一键三连,等待显示一键三连进程结束的时候进入下一个选项卡
首先设置batch_size,建议batch_size设置为显存的一半,高了会爆显存。bs并不是越高越快! GPT模型训练的时候可以把bs再调低点。
接着设置轮数,SoVITS模型轮数可以设置的高一点,反正训练的很快。GPT模型轮数千万不能高于20(一般情况下)建议设置10。然后先点开启SoVITS训练,训练完后再点开启GPT训练,不可以一起训练(除非你有两张卡)!如果中途中断了,直接再点开始训练就好了,会从最近的保存点开始训练。
训练的时候请打开AutoPanel看显卡占用。爆显存了就调低bs。或者存在过长的音频,需要回到2.4步重新制作数据集。
训练完成会显示训练完成,并且控制台显示的轮数停在设置的(总轮数-1)的轮数上。
至于更加详细的数据就需要参考相关论文和文章了
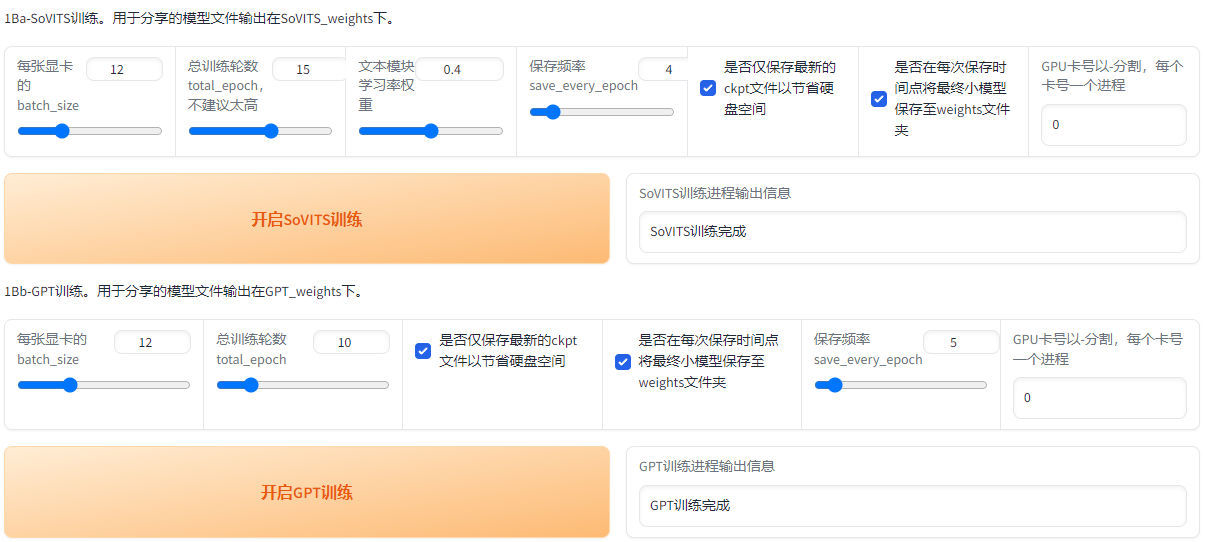
我的设置
训练中...
推理
首先进入第三个选项卡,选择对应的GPT模型和soVITS模型,并开启TTS推理WebUI,然后进入终端中显示的地址打开对应的ui,进行填写即可
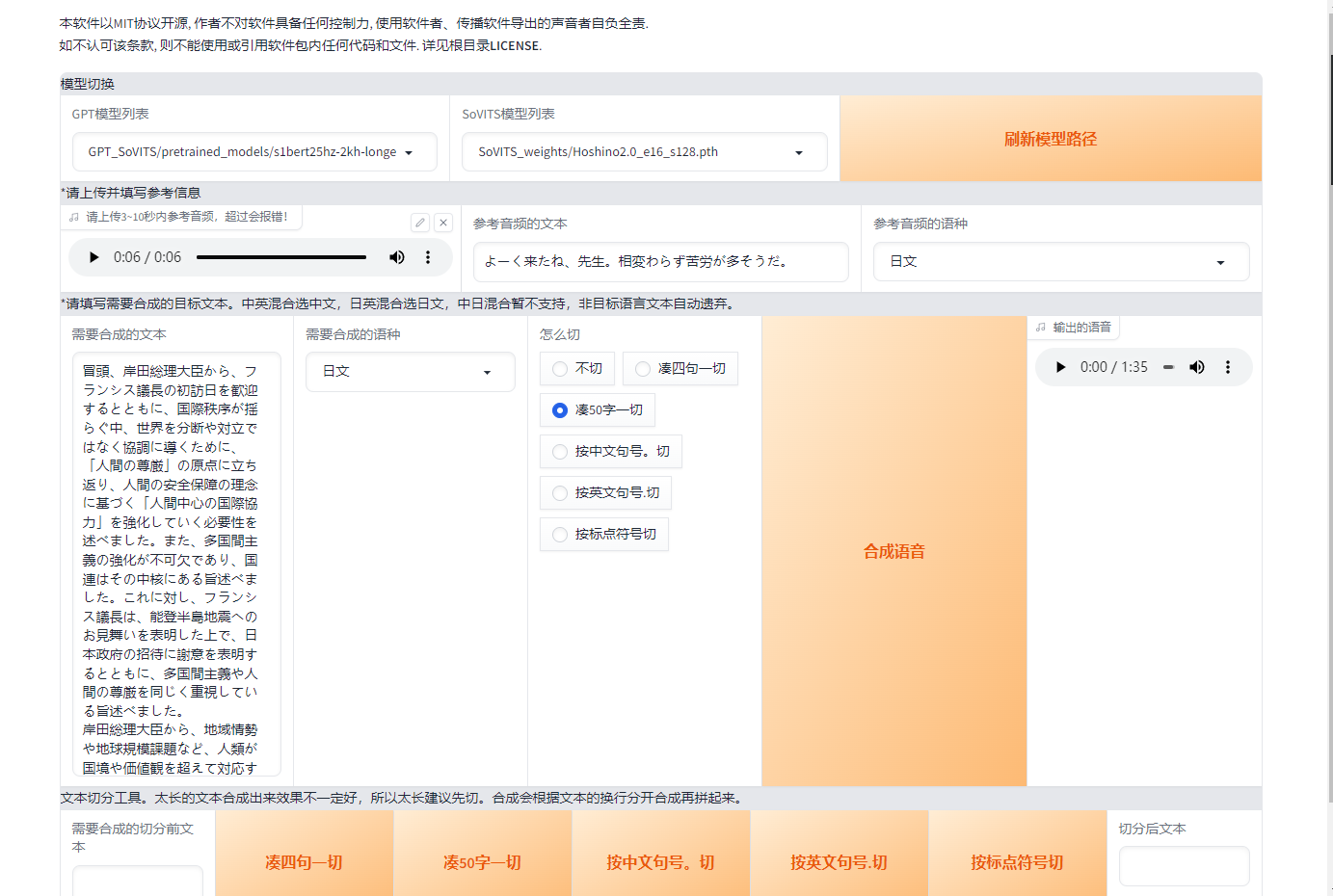
上传一段参考音频,建议是数据集中的音频。最好5秒。参考音频很重要!会学习语速和语气,请认真选择。参考音频的文本是参考音频说什么就填什么,必须要填。语种也要对应
接着就是输入要合成的文本了,注意语种要对应。目前可以中英混合,语种选择中文,日英混合,语种选择日文。切分建议无脑选50字一切,低于50字的不会切。如果50字一切报错的话就是显存太小了可以按句号切。如果不切,显存越大能合成的越多,实测4090大约1000字,但已经胡言乱语了,所以哪怕你是4090也建议切分生成。合成的过长很容易胡言乱语。如果出现吞字,重复,参考音频混入的情况,这是正常现象。不是模型炼差了,不用为模型担心。改善的方法有使用较低轮数的GPT模型、合成文本再短点、换参考音频。官方也在努力修复这个问题。
折腾了一天,其实星野这个数据集由于她的音色非常独特还是非常难练的,明天再试试练一个其他的角色吧。哦对,明天还会被unity暴打捏(笑